近几个月以来,一系列大型语言模型(LLM)相继问世,构建专属的多模态大模型来解决更加复杂的现实任务已经成为了一个重要的研究热点。 虽然各方都急于打造专属于自己的巨型模型,但能够负担得起上亿参数训练成本的机构却寥寥无几。 在快速发展的人工智能领域,高效且有效地利用大型语言模型构建专属的多模态大模型正变得愈发重要。
厦门大学多媒体可信感知与高效计算教育部重点实验室纪荣嵘老师团队,在单张消费级显卡上成功实现了多模态大型模型(LaVIN-7B、LaVIN-13B、LaVIN-30B)的适配和训练。本文旨在详细介绍所采用的技术方案和技术细节,供有相关需求的研究者参考。本研究中采用的模型包括LaVIN(其中语言模型为LLaMA,视觉模型为ViT-L)。通过高效参数训练,LaVIN将LLaMA模型扩展到多模态领域,可用于图文问答、对话以及文本对话等任务。
目前的实验结果显示,7B的多模态大型模型训练(LaVIN-7B)需要大约8~9GB的显存,13B的多模态大型模型训练(LaVIN-13B)需要大约13~14GB的显存。目前这些模型已经能够在单张消费级显卡上完成训练,尽管性能相较于使用fp16精度稍有下降,但仍然极具竞争力。预计65B的模型也将能够在单张A100显卡(40GB显存)上完成训练。所有的训练和测试代码已经全部开源:https://github.com/luogen1996/LaVIN
技术方案
整体的技术方案结合了LaVIN和qlora,主要包含以下几点:
· 参数高效的多模态适配 (大概减少了一大半显存)
· 4bit量化训练 (大概减少了3~8G的固定显存)
· 梯度累计+gradient checkpointing (大概减少了一半多的显存)
· Paged Optimizer (作用不是很明显)
1.参数高效的多模态适配
在此之前先简单介绍一下本文所使用到的核心工作《Cheap and Quick: Efficient Vision-Language Instruction Tuning for Large Language Models》。这个工作提出了一种参数高效的适配方法,能够在将整个LLM参数冻住的情况下实现:
1) 参数高效的多模态大模型适配(仅花费3~6M额外参数)
2) 端到端高效训练 (减少2/3的训练时间)
3) 单模态和多模态的自动切换(兼容不同模态)
在ScienceQA数据集上达到了接近SOTA的性能,同时实现了文本模态和图文模态的同时适配。在显存开销方面,这种参数高效的训练方式可以节约大部分的显存。以LLaVA为比较对象,在完全微调大模型的情况下,LLaVA-13B在A100(80G)上会由于显存不足导致无法微调。相比之下,LaVIN-13B模型在A100显卡(80G)上仅需要约55GB的显存开销即可。 相较于现有的参数高效方法,该方案在性能和适配性方面表现出显著的优势,具体细节可参阅论文,这里不再赘述。
2.4bit量化训练
4bit量化训练主要参考了qlora。简要而言,qlora将LLM的权重量化成为4bit来存储,同时在训练过程中反量化成16bit,以确保训练的精度。因此,该方法非常适合与参数高效的训练方法结合使用。 其主要原理在于将LLM中的所有线性层替换为4bit的量化层。实现代码位于quantization.py和mm_adaptation.py文件中,仅需十来行代码即可实现。
4bit量化训练后,当批大小(batch size)大于1时,显存开销下降并不是特别明显。对于LaVIN-7B模型来说,显存开销大约下降了4~6G,但是这部分的显存下降是固定的,其实非常有价值。此时, LaVIN-7B的显存开销大概还在36+G的水平。
3.梯度累计+gradient checkpointing
这里的关键就在于时间换空间。通过设置batch size=1+梯度累计以及gradient checkpointing的方式能够显著降低显存开销。这也是qlora训练过程中的一个核心策略,因为仅依靠量化训练很难实现显存的极致压缩。实验结果如下:LaVIN-7B在bs=4改成batch size (bs)=1+梯度累计后,显存降低到约25G。经过gradient checkpointing,显存降低至约9~10G。至此,从原先的上百G显存压缩至约10G,虽然训练速度明显变慢,但实际上与qlora原文中的速度下降比例相差无几。相比于原本完全无法训练的情况,这些额外的时间开销显得微不足道。
4.Paged Optimizer
Paged Optimizer的主要作用是在显存不足的情况下,将Optimizer中的一部分权重迁移到CPU上,以确保训练能够正常进行。,这个设置对于显存开销和显卡显存非常接近的情况下可能会发挥一定的作用,能够在紧急情况下起到救急的作用。然而,在正常情况[Gf1] 下,可能并不会有太大的帮助。如果读者对这个设置感兴趣,可以尝试使用8位的Optimizer,或许会带来更明显的效果。
5.性能比较
ScienceQA(多模态科学问答数据集):在ScienceQA上,进行了单卡的情况下完成了4bit训练并和16bit的方法进行了比较。
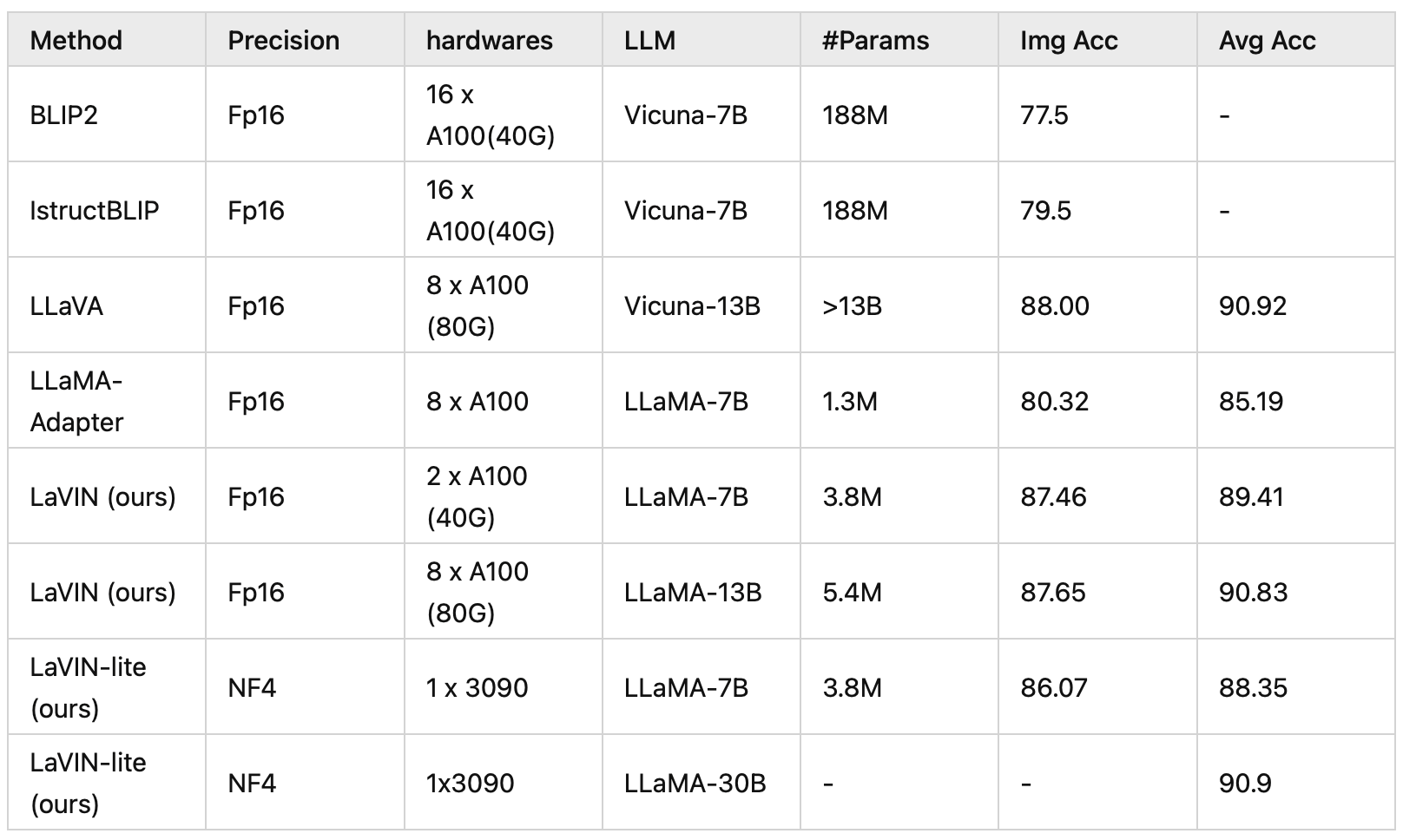
比较结果显示,LaVIN-lite性能仍然远超参数高效的方法LLaMA-Adapter,但是相比较16bit训练的LaVIN,性能出现了略微的下降,但是LaVIN-Lite依然达到了比肩SOTA的性能!
