近日,多媒体可信感知与高效计算教育部重点实验室有6篇论文被人工智能国际顶级会议NeurIPS 2023(Neural Information Processing Systems)录用。录用论文简要介绍如下:
1. Cheap and Quick: Efficient Vision-Language Instruction Tuning for Large Language Models
本文提出了一种新颖且经济实惠的解决方案,用于有效地将 LLMs 适应到 VL(视觉语言)任务中,称为 MMA。MMA 不使用大型神经网络来连接图像编码器和 LLM,而是采用轻量级模块,即适配器,来弥合 LLMs 和 VL 任务之间的差距,同时也实现了图像模型和语言模型的联合优化。同时,MMA 还配备了一种路由算法,可以帮助 LLM 在不损害其自然语言理解能力的情况下,在单模态和多模态指令之间实现自动切换。
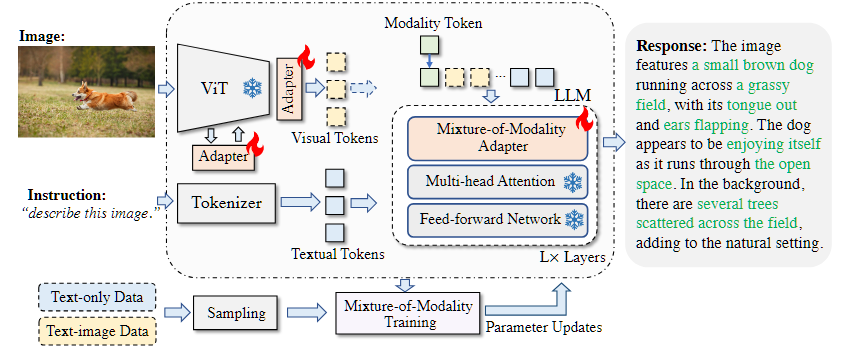
论文第一作者是人工智能系2021级博士生罗根,通讯作者是纪荣嵘教授,由周奕毅副教授、孙晓帅副教授和2022级硕士生陈晟新等共同合作完成。
2. Improving Adversarial Robustness via Information Bottleneck Distillation
本文提出了信息瓶颈蒸馏(IBD)方法,用两种蒸馏策略来分别匹配信息瓶颈的两个优化过程。首先,利用鲁棒的软标签蒸馏来最大化潜在特征和输出预测之间的互信息;其次,提出了一种自适应特征蒸馏,可以自动将相关知识从教师模型转移到目标模型,从而可以限制输入特征和潜在特征之间的互信息。本文方法在各种基准数据集进行了广泛的实验,实验结果证明了所提出的方法可以显著提高模型的对抗鲁棒性。
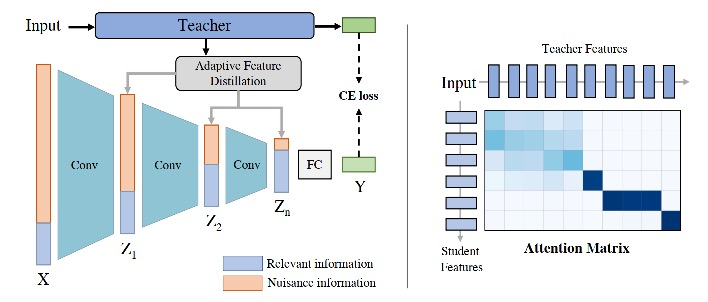
论文第一作者是人工智能系2020级博士生匡华峰,通讯作者是纪荣嵘教授,由刘宏博士(日本国立信息研究所)、Shin’ichi Satoh教授(日本国立信息研究所)、吴永坚(腾讯优图)等共同合作完成。
3. Parameter and Computation Efficient Transfer Learning for Vision-Language Pre-trained Models
近年来,视觉语言预训练(VLP)模型的规模和计算量不断增加,导致将这些模型迁移到下游任务时的开销也越来越大。最近的研究重点关注了VLP模型参数高效迁移学习(PETL),该方法仅需更新少量参数即可实现模型任务迁移。然而,大量的计算开销仍然困扰着VLP的应用。因此,本文致力于研究VLP模型参数和计算的高效迁移学习(PCETL)。需要特别注意的是,PCETL不仅要限制VLP模型中可训练参数的数量,还注重减少推理过程中的计算冗余,以实现更高效的传输。为实现这一目标,本文提出了一种新的动态架构跳过(DAS)方法。DAS不是直接优化VLP模型的内在架构,而是通过基于强化学习的过程观察模块对下游任务的重要性,然后使用轻量级网络跳过冗余模块。这样一来,VLP模型的迁移过程能够有效地将可训练参数保持在较低水平,同时加快对下游任务的推理速度。
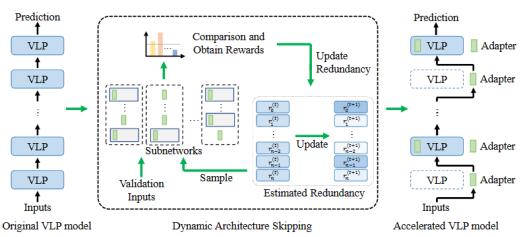
论文第一作者是人工智能研究院2022级博士生吴穹,通讯作者是纪荣嵘教授,由2022级硕士生余薇、周奕毅副教授、2021级硕士生黄书滨等共同合作完成。
4. E2PNet: Event to Point Cloud Registration with Spatio-Temporal Representation Learning
作为一种新型异步视觉传感器,事件相机具有极高的时间分辨率和动态范围,能高性价比地应用于高速、高动态场景。在事件相机中,各像素对超过阈值的光照变化进行异步脉冲响应。这一独特的异步数据流对现有的同步数据处理方式带来了新的挑战。现有方法在事件表示过程中损失了大量的时间细节与时空关联信息,不利于高速、高动态场景。针对这一问题,本论文提出将原始事件相机数据建模为特殊时空点云,使用基于点的学习方法自适应地提取重要的时间细节和时空关联信息,并将其表示为网格化特征向量。论文提出的时空分离注意力机制有效的克服了事件数据中时间与空间维度的不同物理意义、量纲、分布带来的挑战,并且能够以模块化方式嵌入现有事件相机相关算法中。提出的事件学习表示模块可结合后续任务进行端到端学习达到更好的性能。论文在事件-三维点云模型注册任务的多个场景中进行了充分实验,证明了本文表示学习方法的有效性。同时,该方法直接嵌入各类基于事件相机的光流估计、目标识别等任务中同样取得了性能提升,证明了该方法在其他任务中具有泛化性。
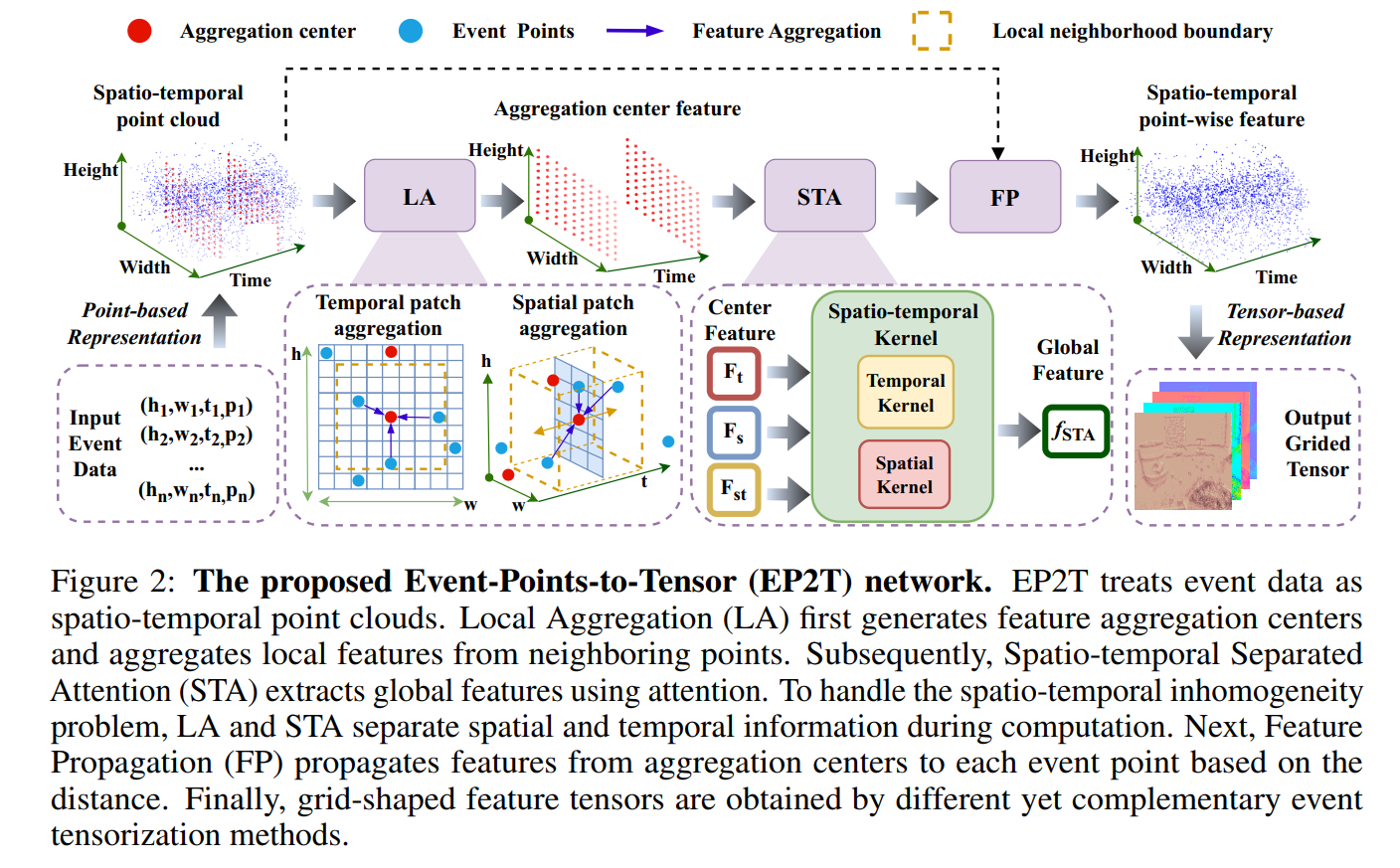
论文共同第一作者是信息学院博士生林修弘和硕士生邱畅杰,通讯作者是沈思淇助理教授,由王程教授、臧彧副教授、刘伟权博士、蔡志鹏博士(英特尔公司)、Matthias Müller博士共同完成。
5. RiskQ: Risk-sensitive Multi-Agent Reinforcement Learning Value Factorization
这个工作是信息学院NeurIPS 2022年亮点论文ResQ的扩展和深化。传统的多智能体价值分解算法普遍通过最大化Q值(价值分布的期望)来选取智能体的最优动作。但是在具有高度不确定性的多智能体环境中,由于存在着一些会带来极高/低奖励的小概率事件,因此最大化期望值的算法并不总能保证得到最优解。针对这一问题,本论文对多智能体协同强化学习中常用的个体全局最优化原则(IGM)进行了扩展,提出了风险敏感的个体全局最优化原则(RIGM),并在理论上证明了现有的主流价值分解算法无法满足RIGM原则。之后,本论文提出了RiskQ(基于风险函数的价值分解方法),将联合价值分布建模为个体价值分布的带权分位数混合的形式,通过理论验证其能够满足RIGM原则,且适用于任意扭曲风险指标(Distorted Risk Measure)。论文在悬崖环境、跟车环境以及包含星际争霸游戏的多个场景中进行了充分实验,证明了RiskQ方法的有效性。

论文第一作者是信息学院沈思淇助理教授,通讯作者是符永铨副教授(国防科技大学),由计算机科学与技术系2022级硕士生马陈楠、2022级硕士生李超、刘伟权博士、王程教授、梅松竹副教授(国防科技大学)、刘新旺教授(国防科技大学)等合作完成。
6. Learning Re-sampling Methods with Parameter Attribution for Image Super-resolution
目前主流的深度超分模型主要关注网络架构设计以及优化策略,忽略了对训练数据的关注。事实上,大多数超分方法都是在整幅图像上通过随机采样图像块对来训练模型。然而,图像内容的不均匀性使得训练数据呈现不平衡分布,即易重构区域(平滑)占据了大部分数据,而难重构区域(边缘或纹理)的样本很少。基于这个现象,本论文考虑重新思考当前仅使用统一数据采样方式训练超分模型的范式,提出了一种简单而有效的双采样参数归因方法,其中双采样包括均匀采样和反转采样,通过引入反转采样来调和不平衡的数据偏差。前者旨在保持数据的原始分布,后者旨在增强模型对困难样本的特征提取能力。此外,引入积分梯度对两种采样数据交替训练的模型中每个参数的贡献进行归因,从而筛选出不重要的参数进行进一步细化。通过逐步解耦参数的分配,超分模型可以学习到更紧凑的表示。在公开数据集上的实验表明,本论文所提方法可以显著提升基线模型的性能。
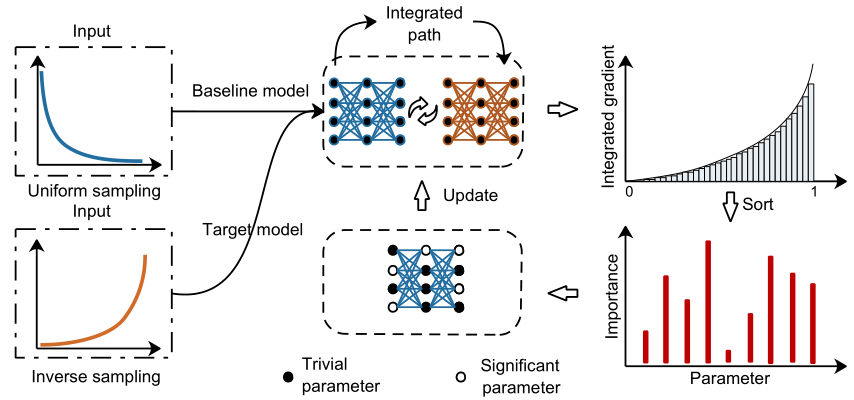
论文第一作者是信息学院计算机科学与技术系2020级博士生罗小同,通讯作者是曲延云教授,合作者还有谢源教授(华东师范大学)。
